这是摘要
[TOC]
引言
是什么
jvm 是什么?
java virtual machine, java程序(二进制字节码)的运行环境
好处?
- 一次编写到处运行的基础,屏蔽字节码对底层操作系统的差异
- 自动内存管理,垃圾回收功能
- 数组下标越界检查
- 多态
比较jre jdk jvm
jvm < jre (jvm 基础类库) < jdk (jvm 基础类库 编译工具) < 开发JavaSE程序 (jdk IDE) < 开发JavaEE程序 (jdk 应用服务器 IDE)
学习路线
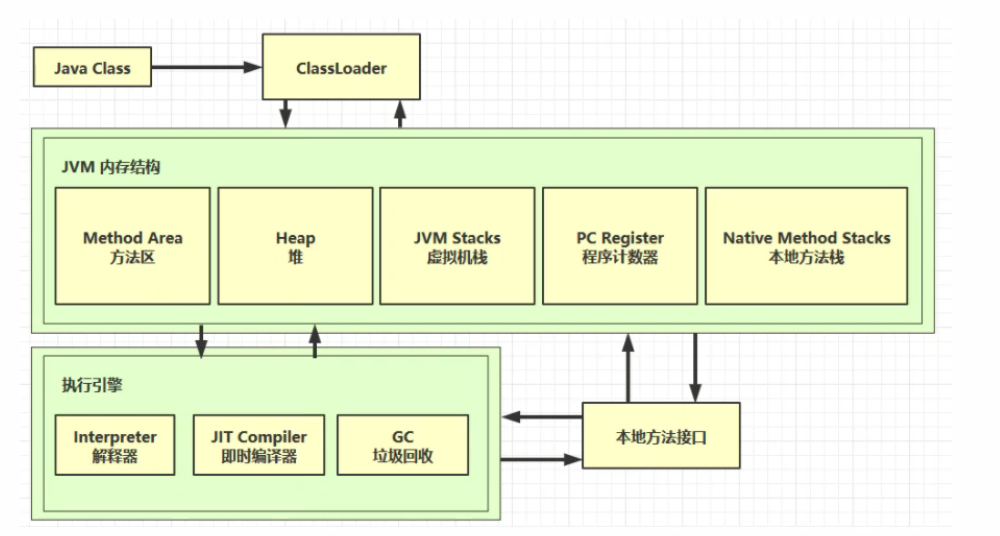
JVM内存结构
程序计数器(寄存器)
定义
program counter register
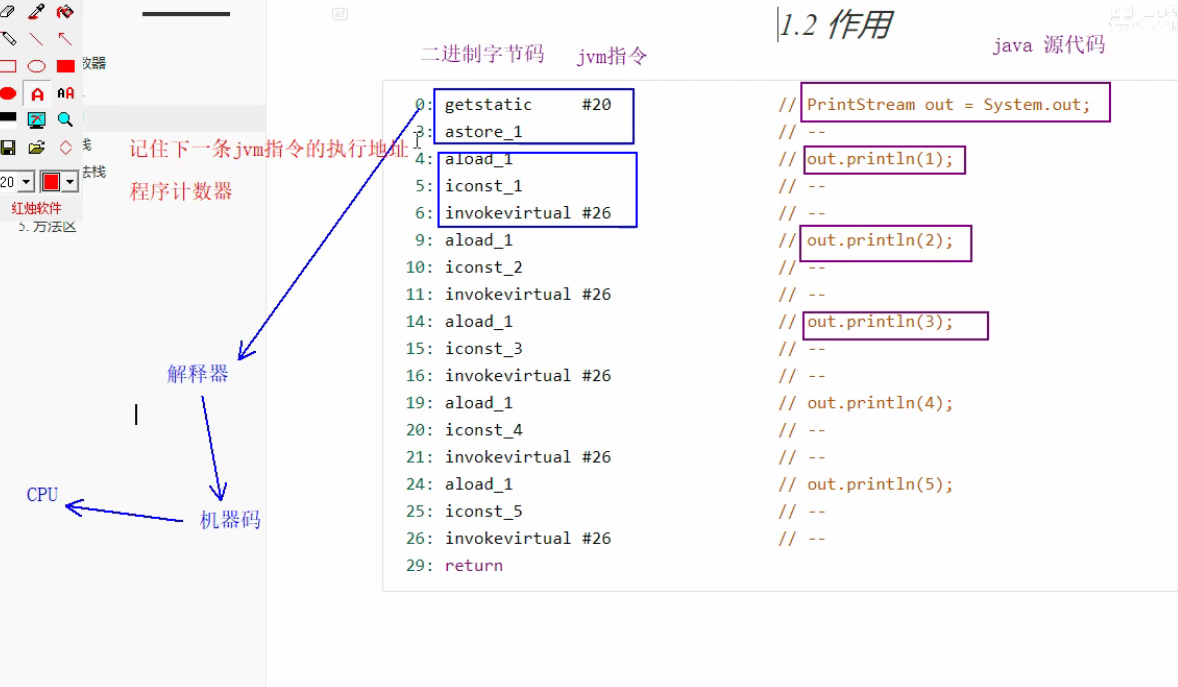
作用
- 记住下一条jvm指令的地址
- 特点
- 线程私有,每个线程有自己的程序计数器
- 不会存在内存溢出
虚拟机栈
定义
线程运行需要的内存空间
基本单位是栈帧,一个栈帧可以看做一次方法调用
- 参数
- 局部变量
- 返回地址
栈顶对应着正在运行的方法
栈内存
关于栈内存
- 机器的物理内存一定,如果栈内存分配越大,能够产生的线程数就越小
- 不会影响运行效率
局部变量线程安全
一般变量:如果作用域封闭,由于栈独立,互不干扰,所以是线程安全的
static:由于存在共享,所以有问题
线程运行诊断
案例1:cpu占用过多
定位:
top # 定位进程
ps H -eo pid,tid,%cpu | grep ${pid} # 定位线程
jstack ${pid}
案例2:死锁
本地方法栈
本地方法 native method
非java编写,通常是一些操作系统级的底层方法
堆
定义
- 通过
new关键字,创建对象都会使用堆内存 - 线程共享,堆中的对象需要考虑线程安全问题
- 有垃圾回收
不是说 局部变量是在虚拟机栈中的吗
堆内存溢出
-Xmx8m 设置堆内存为8m
堆内存诊断
jps、jmap(查看堆内存占用情况)、jconsole
jmap -heap <pid>
案例,垃圾回收后,内存占用依旧很高
jvisualvm 堆转储 dump下来查看内存快照
方法区
定义
概念上的一个区域,具体的实现方式不同。主要有运行时常量池、类相关信息、类加载器等内容
在Oracle的hotspot实现中,1.6实现方式为永久代,1.8实现方式为元空间。
方法区元空间内存溢出
-XX:MaxMetaspaceSize=8m
ClassLoader用来加载类的二进制字节码
如果.class过多
OutOfMemoryError
常量池
二进制字节码(类基本信息、常量池、类方法定义(包含虚拟机指令))
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的雷鸣、方法名、参数类型、字面量等信息
- 运行时常量池,常量池存在*.class文件中,当该文件被加载,他的常量池信息就会放入到运行时常量池,并把里面的符号地址改变为真实地址
// 常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为java字符串对象
// 当执行过具体的java字节码后(eg. ldc #2),会符号会变为对应字符串对象
// StringTable ["a", "b", "ab"] hashtable 结构, 不能扩容
public static void main() {
String s1 = "a"; // ldc #2;
String s2 = "b"; // ldc #3
String s3 = "ab"; // ldc #4
String s4 = s1 + s2; // new StringBuilder().append(s1).append(s2); <=> new String("ab");
sout( s3 == s4 ); // Q1
String s5 = "a" + "b"; // ldc #4
sout ( s3 == s5 ); // Q2
}
- Q1: s3的字符串对象是在串池中的,而s4的是new出来的,在堆中,所以结果是false
- Q2: 同样是常量,在串池中,true
StringTable特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder
- 字符串常量拼接的原理是编译器优化
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池,并返回串池中的对象(1.6动作不一样)
1.6时 StringTable在常量池中,1.8时 移出到堆中;是一种GC触发频率的优化
StringTable垃圾回收
-Xmx10m 堆内存最大值
当堆内存空间不足时,垃圾回收同样会对StringTable进行处理
StringTable性能调优
底层是HashTable,就那种用数组做的Hash表
-XX:StringTableSize=10000数组长度,增大能明显减少碰撞率
案例:大量字符串,且高概率存在重复,入池能大幅减少内存耗费
直接内存
定义
非JVM部分,指操作系统内存
- 常见于NIO操作时,用于数据缓冲区
- 分配回收成本较高,但是读写性能强
- 不受JVM内存回收管理
NIO 一般指使用ByteBuffer进行读写;相对的传统读写方法如FileInputReader
传统IO
CPU:用户态-》内核态-》用户态
内存:磁盘文件-》系统缓存区-》java 缓冲区byte[]
直接内存 Buffer.alocateDicrect(size)
CPU:用户态-》内核态-》用户态
内存:direct memory 由操作系统和java程序共享
分配/回收
unsafe对象主动管理,不是由GC回收
-XX:+DisableExplicitGC 禁用显式的垃圾回收,会使System.gc() FULL GC无效,也就会影响到使用该函数对direct memory的回收
所以建议直接用unsafe回收
垃圾回收
如何判断对象可以回收
引用计数法
被引用计数为0时,即可回收
循环引用,无法被回收,造成内存泄漏
可达性分析法
根对象:肯定不能当成垃圾的对象
回收前扫描所有存活对象,如果被跟对象直接间接引用,则不回收
那些对象可以作为GC root?
工具 Memory Analyzer (MAT) by eclipse
一些jdk核心类、线程使用中的类、锁、native方法引用的java对象
四种引用
- 强引用 x = new x() ,无root引用时可回收
- 软引用,无root直接引用且内存不足时可回收
- 弱引用,无root直接引用时可回收
- 虚引用,引用的对象回收掉后自身进入引用队列,有一个ReferenceHandler线程定期调用其特定方法,清理内存(如直接内存中的Cleaner)
- 终结器引用,如果类重写了finallize(),对象将要被回收时,将虚拟机为其创建的终结器引用放入引用队列,再由一个finalizeHandler线程,扫描队列,从终结器引用找到对象,调用其finallize(),下一次垃圾回收时,真正回收
软引用,软引用对象产生的一种引用关系
如果有回收队列,软/弱引用对象引用的对象被回收后,可进入引用队列,等待释放其自身占用的内存
虚引用和终结器引用必须配合引用队列
SoftRenference<T> 软引用场景:例如图片缓存
ReferenceQueue<T> 清理无用的软引用对象
WeakReference<T>
垃圾回收算法
标记清除(Mark Sweep)
- 扫描确定清除对象 - 标记
- 释放标记的对象(内存区域记为空闲) - 清除
- 速度快
- 容易产生内存碎片
标记整理(Mark Compact)
- 标记
- 清除 并移动内存整理内存碎片
- 效率较低
- 没有内存碎片
复制(Copy)
设置两块内存区域,
- 标记
- 回收时将FROM区域的存活对象移动到TO区域并保持紧凑
- 清空FROM区域
- 交换FROM和TO的标记
- 不会产生碎片
- 会占用双倍的内存空间
分代垃圾回收
结合上述算法。
内存划分
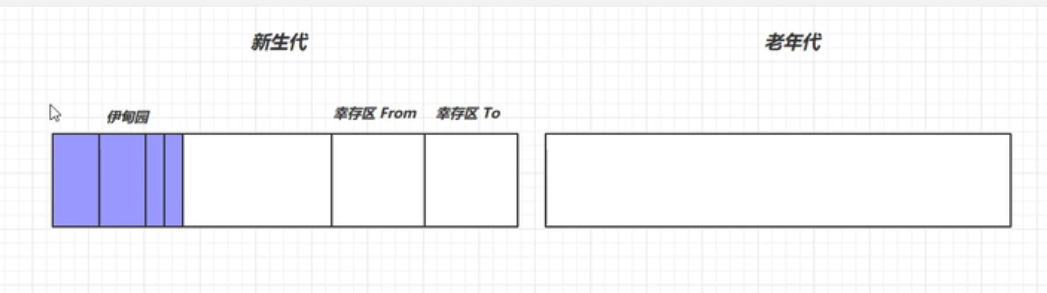
长时间使用放在老年代,用完就丢放在新生代
- 新对象分配到 Eden
- 空间不足是发生 Minor GC
- (minor gc 会触发 The World,暂停所有其他用户线程,因为对象地址会变动)
- 复制算法,复制到 幸存区TO,这些对象寿命+1
- 交换FROM TO标记
- 再次MinorGC(Eden+FROM),幸存区寿命达到阈值(最大15)的对象进入老年代
- 老年代空间不足,先minor gc,仍不足,触发FULL GC。STW时间更长
如果新生代此时已经超额了也会放入老年代?
大对象直接晋升到老年代,超过新生代容量
子线程的内存溢出不会导致主线程结束
相关VM参数

垃圾回收器
串行
- 单线程
- 适合堆内存较小,cpu个数少
-XX:+UseSerialGC=Serial+SerialOld(copy + mark compact)
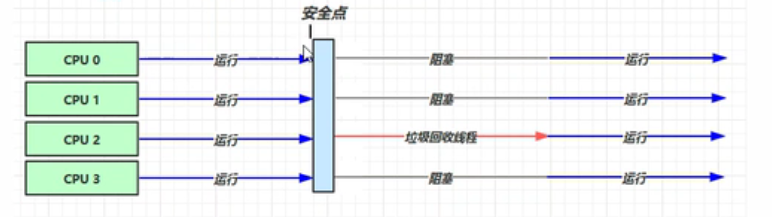
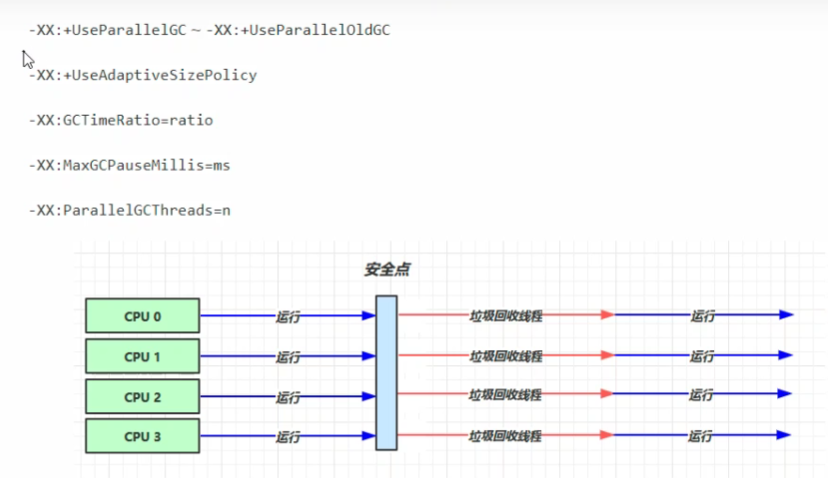
安全点,保证回收后对地址的引用不会混乱。活动帧释放?
吞吐量优先
- 多线程
- 堆内存较大,多核cpu
- 让单位时间内STW时间尽可能短
(copy + mark compact)
响应时间优先
- 多线程
- 堆内存较大,多核cpu
- 让单次的STW时间尽可能短
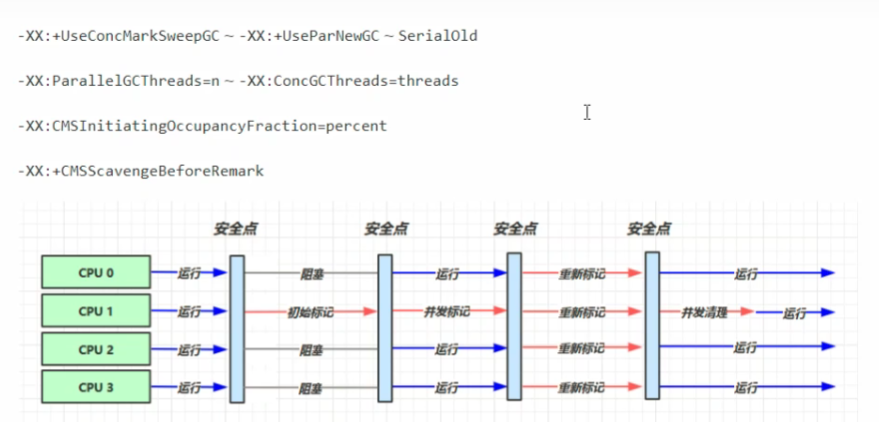
这是老年代的清除过程 (mark sweep)(并发失败退化为串行)
初始标记根对象(STW),并发标记所有对象(并发),重新标记(STW,避免并发时的引用)
浮动垃圾得等到下次GC才能被清除,所以需要预留空间给浮动垃圾
G1
定义:Garbage First
适用场景
-
并发的垃圾回收器
- 同时注重吞吐量(Throughput)和低延迟(Low latency),默认的暂停目标是200ms
- 超大内存堆,会将堆划分为多个大小相等的Region
- 整体上是mark compact算法, 两个区域之间是copy算法
相关JVM参数
-XX:+UseG1GC
-XX:G1HeapRegionSize=size
-XX:MaxGCPauseMillis=time
G1回收阶段
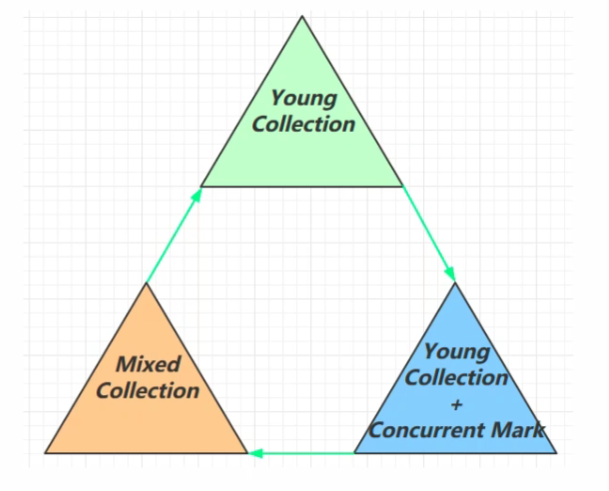
Young Collection
- 有STW
- 幸存对象拷贝进Surviver,够年龄的进入Old
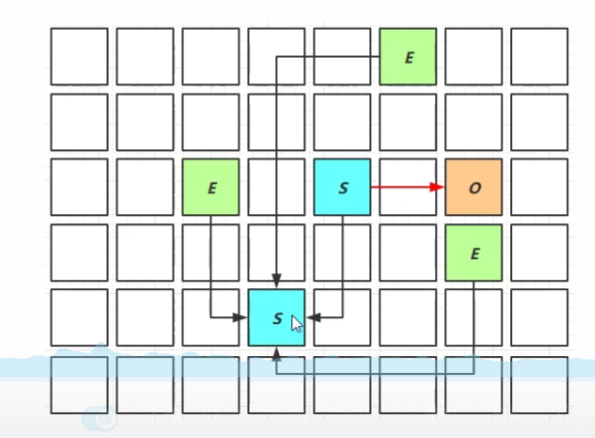
跨代引用
- 老年代区域划分为一片片卡(一般512k)
- 如果某卡内的对象引用了新生代对象,记为脏卡
- 通过脏卡标记,减少查找 GC Root 的时间
- 新生代有一个 Remembered Set 记录自己被谁引用了,也就是脏卡的位置
- 在引用变更时,通过一个写屏障将记录脏卡的指令异步存入一个队列
- 由一个 concurrent refinement threads 读取指令更新 Remembered Set
Young Collection + Concurrent Mark
- Young GC时会进行初始标记
- 老年代占用空间比例达阈值时,进行并发标记;参数
-XX:InitiatingHeapOccupancyPercent=percnet(45%)
Mixed Collection
- 会对Eden、Surviver、Old进行全面GC
- 最终标记(Remark)有STW
- 拷贝存活(Evacuation)有STW
-XX:MaxGCPauseMillis=ms
Old优先收集垃圾最多的区域,以缩短暂停时间
Remak
在并发标记阶段,已经处理过的对象不会进行第二次判断
如果对象B在被处理时被判断为垃圾,但是由于并发,用户线程的其他操作使B成为了A的强引用
在这个引用关系发生时,一个写屏障指令会触发,将B放入一个队列中,将B标记为待处理
重标记阶段时,发生STW,对队列中的待处理对象进行重新判断
pre-write barrier+ satb_mark_queue
JDK 8u20 字符串去重
- 优点:节省大量内存
- 缺点:略微多占用了CPU时间,新生代回收时间略微增加
-XX:+UseStringDeduplication
- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1并发检查是否有字符串重复
- 如果他们值一样,使之引用同一个
char[] - 注意,与
String.intern()不一样String.intern()关注的时字符串对象- 这里关注的时
char[] - 在JVM内部使用了不同的字符串表
JDK 8u40 并发标记类卸载
所有对象都经过并发标记后,就能够知道那些类不再使用(没有存活实例),当一个类加载器的所有类都不再使用,则卸载它所加载的所有类
通常发生在自定义类加载器
-XX:+CkassUnloadingWithConccurentMark默认启用
JDK 8u60 回收巨型对象
- 当一个对象大于region的一半时,称为巨型对象
- G1不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1会跟踪从老年代到巨型对象的所有incoming引用,这样当老年代incoming引用为0的巨型对象就可以在新生代垃圾回收时处理掉(尽早处理)
JDK 9 并发标记起始时间的调整
- 并发标记必须在堆空间占满时完成,否则退化为 full gc
- 使混合收集提前开始,就能够减少 full gc 的发生
- JDK 9 之前需要使用
-XX:InitiatingHeapOccupancyPercent - JDK 9 可以动态调整
-XX:InitiatingHeapOccupancyPercent用来设置初始值- 进行数据采样并动态调整
- 总会添加一个安全的空档空间
GC 发生时间辨析
- Serial GC
- 新生代内存不足 - minor gc
- 老年代内存不足 - full gc
- Parallel GC
- 新生代内存不足 - minor gc
- 老年代内存不足 - full gc
- CMS
- 新生代内存不足 - minor gc
- 老年代内存不足 - 同下
- Serial GC
- 新生代内存不足 - minor gc
- 老年代内存不足
- 并发垃圾收集速度大于产生速度 - 并发标记、混合收集
- 反之 - full gc (退为串行)