[TOC]
并发
进程&线程
进程
- 程序由指令和数据组。指令加载至CPU,数据加载至内存,另外还可能需要用到其他设备如磁盘。进程即用来加载指令、管理内存、管理IO
- 程序被运行(从磁盘加载程序代码到内存),就开启一个进程
- 进程可以视为程序的一个实例,大部分程序可以同时运行多个进程(程序多开)
线程
- 一个进程之内可分一到多个线程
- 一个线程就是一个指令流,将指令流中的一条条指令顺序交给CPU执行
- java中,线程时最小调度单位,进程是最小资源分配单位。windows中进程不活动,作为线程的容器
对比
- 进程基本相互独立;线程存在与进程内,是其子集
- 进程拥有共享的资源,如内存空间等,供内部的线程共享
- 进程通信比较复杂
- 线程通信因为共享内存,比较简单
- 线程的上下文切换成本更低
并发
微观串行,进程轮流使用CPU,concurrent
并行
多核CPU,parallel
应用
- 同步,需要等待结果返回才能继续运行
- 异步,不需要等待就能继续运行
tip:同步另有让多个线程步调一致的意思
结论
- 单核cpu下,多线程不能实际提高程序计算效率,只是为了能够在不同的任务之间切换,不同线程轮流使用cpu,不至于一个线程总占cpu,别的线程没法干活
- 多核cpu可以并行跑多个线程,能否提高效率在于任务设计拆分,参考【阿姆达尔定律】
- IO不占用cpu,但是线程等待IO称为【阻塞IO】。后有改进的【非阻塞IO】、【异步IO】
Java线程
五种状态
创建、就绪、运行、阻塞、终止
六种状态(Thread.State)
NEW RUNNABLE BLOCKED WAITING TIMED_WAITING `TERMINATED
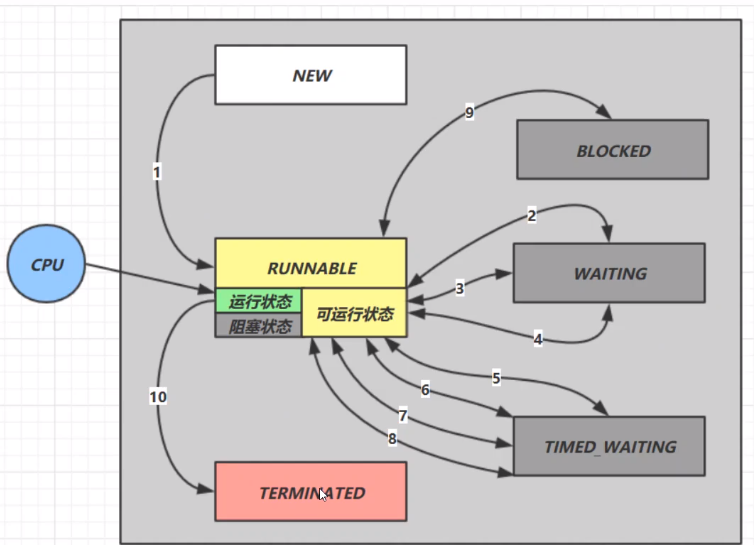
startwait/notifyinterruptjoinpark/unparkwait(n)join(n)sleep(n)parkNannos(n) parkUntil(n)- 竞争锁失败
创建和运行线程
方法一 直接使用Thread
Thread t = new Thread() {
public void run() {
// some things
}
};
t.start();
方法二 使用Runnable配合Thread
Runnable runnable = () -> {...};
Thread t = new Thread(runnable);
t.start();
线程与任务分离;更容易与线程池等API配合;任务类脱离Thread继承体系,更灵活
方法三 FutureTask配合Thread
FutureTask接收Callable类型参数,处理有返回结果的情况
FutureTask<Integer> task = new FutureTask<>(() -> {
log.info("Future Task running...");
Thread.sleep(1000);
return 100;
});
Thread t = new Thread(task, "t1");
task.get();
查看进程线程的方法
windows
- 任务管理器可以查看进程和线程数
tasklisttaskkill
Linux
ps -fe查看所有进程ps -fT -p <PID>查看某个进程的所有线程kill关闭进程top按大写H切换是否显示线程top -H -p <PID>查看某个进程的所有线程
Java
jps查看所有java进程jstask <PID>查看某个java进程的所有线程状态jconsle查看某个Java进程中线程的运行情况
线程运行原理
栈&栈帧
JVM由堆、栈、方法区组成;线程使用栈
- 栈有多个栈帧,对应着每次方法调用时所使用的内存
- 每个线程只能有一个活动栈帧,对应正在执行的方法
多线程时,各线程的栈帧独立
上下文切换
因为一下一些原因CPU不再运行当前线程,转而执行另一个线程的代码:
- 线程时间片到
- 垃圾回收
- 有更高级的线程需要运行
- 线程自己调用了sleep、yield、wait、park、synchronized、lock等方法
当上下文切换发生时,由操作系统保存当前线程的状态,并恢复另一个线程的状态。java中程序计数器完成这个操作,记住下一条jvm指令的执行地址,等
频繁的上下文切换会影响性能
常见线程方法

start & run
直接调用Thread对象的run方法,不会开启新的线程,而是在当前线程执行
sleep & yield
sleep
- 线程会从Running进入Timed Waiting状态(阻塞)
- 线程睡眠中可被调用interrupt打断,抛出InterruptException
- 睡眠结束的线程未必立刻得到执行
- 建议使用
TimeUnit.sleep()代替Thread.sleep(),可读性好点
yield
- 调用yield的线程会让出当前CPU,从Running进入Runnable(就绪)
线程优先级
- 线程优先级提示(hint)调度器优先调度该线程,具体由调度器决定
- 如果cpu忙,较高优先级线程可能获得更多时间片;如果闲,优先级没啥用
案例:防止CPU100%
sleep实现
在没有利用cpu来计算时,不要让while(1)空转浪费cpu,这是可以用yield或sleep来让出cpu的使用权给其他程序
//在while(1)中
sleep(50); //一个较短的时间,仅是为了让出cpu防止空转
适用于无需锁同步的场景
jion方法
考虑如下情况,r无法获得更新后的值
static int r = 0;
public static void main(String[] args) throws InterruptedException {
test();
}
private static void test() throws InterruptedException {
Thread t1 = new Thread(() -> {
sleep(1);
r = 10;
}, "t1");
t1.start();
log.info("r: {}", r);
}
t1.start();
t1.jion();
log.info("r: {}", r);
主线程进行到jion时阻塞,等待t1线程执行完毕
interrupt方法
打断阻塞状态(sleep、wait、join),打断后打断标记其实是false
打断正常运行线程,线程不会直接停止,打断标记会变成true
两阶段终止模式 (Two Phase Termination)
stop()直接杀死线程,如果线程拿了锁,就没机会释放
样例:一个可中止的系统状态监控程序
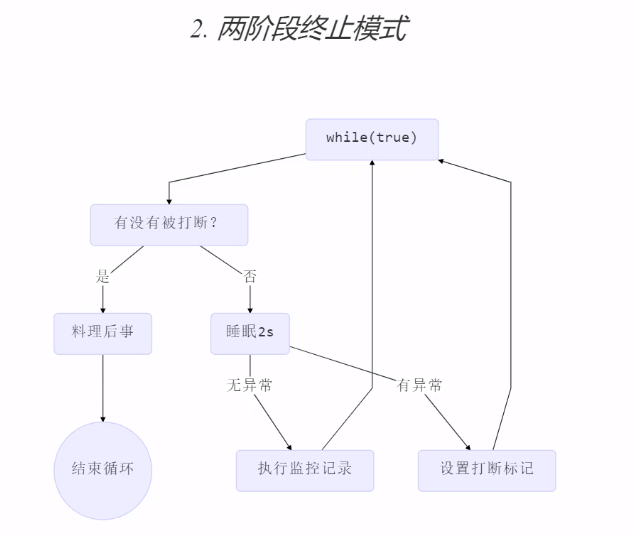
@Slf4j
public class TwoPhaseTermination {
private final Thread monitor = new Thread(()->{
while(true){
Thread currentThread = Thread.currentThread();
if (currentThread.isInterrupted()){
// 处理后事
log.info("处理后事");
break;
}
try {
TimeUnit.SECONDS.sleep(2);
// 监控
log.info("监控状态");
} catch (InterruptedException interruptedException) {
// sleep被打断会清除打断标记
// 重新设置打断标记
currentThread.interrupt();
}
}
}, "monitor");
public void start(){
monitor.start();
}
public void stop(){
monitor.interrupt();
}
}
打断park线程
LockSupport.park()
打断parking线程,打断标记变为true;当打断标记已为true时,调用park将不会再停止
Tread.interrupted() 返回当前打断标记,然后将其置为false
Balking模式
Balking(犹豫)用在一个线程发现将要运行的任务重复,则直接返回
private volatile boolean running = false;
public void start(){
synchronized(this) {
if (running) return;
running = true;
}
// ...
}
主线程与守护线程
默认情况下,Java进程需要的等待所有线程运行结束才会结束。有一种特殊的线程叫守护线程,只要其他非守护线程全部结束,即使守护线程仍在进行,也会强制结束
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
break;
}
}
log.info("t1 结束");
}, "t1");
t1.setDaemon(true);
t1.start();
TimeUnit.SECONDS.sleep(1);
log.info("main 结束");
}
GC是守护线程
守护线程的守护含义是?
共享模型-管程(Monitor)
多线程下使用共享变量的问题
如果对共享变量的读写不具有原子性,一个线程的结果可能因为线程切换没来得及写入(指令交错),当再切换回时进行的写入会覆盖其他线程的原子操作
对共享资源的多线程读写操作代码块,称为临界区
多个线程在临界区内执行,由于代码的执行顺序不同而导致结果无法预测,称之为发生了竞态条件
避免临界区的竞态条件发生
- 阻塞式:synchronized,Lock
- 非阻塞式:原子变量
synchronized-互斥
即对象锁
语法
synchronized(obj){
// 临界区
}
synchronized void fun(){...}
//等价于
void fun(){
synchronized(this){...}
}
synchronized static void fun(){...}
//等价于
static void fun(){
synchronized(Clazz.class){...}
}
变量的线程安全分析
成员变量和静态变量
- 没有共享,线程安全
- 读共享,线程安全
- 读写共享,需要考虑
局部变量
- 局部变量线程安全
- 局部变量引用的对象
- 该对象没有逃离方法的作用范围,线程安全
- 该对象逃离方法的作用范围,需要考虑
局部变量
public static void test(){
int i = 10;
i++;
}
局部变量在栈帧中各自创建,不存在共享
局部变量引用
public class TestThreadUnsafe {
public static void main(String[] args) {
ThreadUnsafe test = new ThreadUnsafe();
new Thread(test::fun, "Thread-1").start();
new Thread(test::fun, "Thread-2").start();
}
}
class ThreadUnsafe{
List<Object> list = new ArrayList<>();
public void fun(){
for (int i=0; i<1000; i++){
add();
remove();
}
}
private void add() {
list.add(new Object());
}
private void remove() {
list.remove(0);
}
}
两个线程引用了同一个对象,增减操作不具备原子性,线程不安全
常见线程安全类
String、Integer、StringBuffer、Random、Vector、HashTable、java.util.concurrent
具体指,当多个线程调用这些类的一个实例时,是线程安全的,即方法具有原子性
但,多个方法的组合不是原子性的,如if(table.get("key") == null) {table.put("key", "value")}
String、Integer等不可变类,在修改时实际返回的是新对象的引用
不可变类的修饰通常为final就是为了防止被继承破坏不可变的特性
Monitor概念
Java对象头
普通对象
Object Header (64btis)
Mark Word (32bits) | klass Word (32bits)
数组对象
Object Header (64btis)
Mark Word (32bits) | Klass Word (32bits) | Array Length (32bits)
Mark Word结构
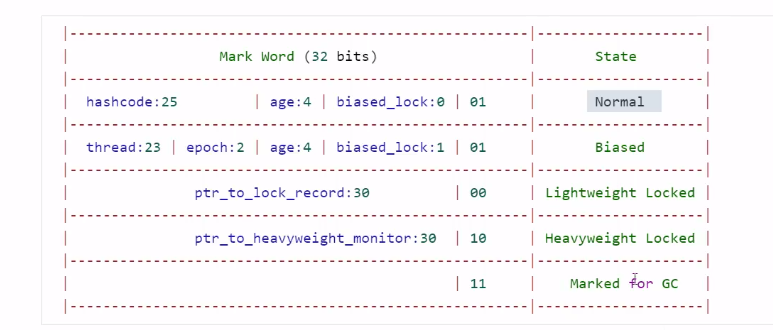
tip:每一行代表MarkWord所处的一种状态
Monitor(锁)
监视器 or 管程
每个Java对象都可以关联一个Monitor对象,如果使用synchronized给对象上锁(重量级)之后,该对象头的Mark Word中就被设置指向Monitor对象的指针(进入重量级锁状态)
Monitor结构如图
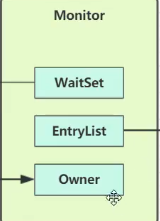
线程执行到临界区时,通过上锁对象去发现其指向的Monitor
- 初始Monitor的Owner为null
- 线程1进入临界区,将Owner值为线程1
- 线程2、线程3进入临界区,进入EntryList指向队列,进入BLOCKED状态
- 线程1执行完临界区,让出Owner,Monitor通知EntryList,阻塞进程自行竞争
- WaitSet中存放获得过锁,但资源条件不满足而进入WAITING状态到的线程
synchronized优化
轻量级锁
当线程对共享资源的使用时间往往错开,竞争较小时,Monitor的资源开销显得较大。这时使用轻量级锁;
如果轻量级锁使用过程中发生了竞争,则升级为重量级锁
- 线程对一个对象获得锁
- 在栈中创建一个锁记录,包含锁记录地址、对象引用
- 加锁
- 获得锁成功,锁记录地址与对象头MarkWord交换
- 获得锁失败。1. 说明其他进程获得过该对象轻量级锁,进入锁膨胀过程;2. 线程自身获得过一次该对象轻量锁,再添加一条锁记录作为重入计数
- 解锁
- 解重入,去掉锁记录
- 解轻量,MarkWord恢复给对象头
- 失败,说明发生了锁膨胀,已经升级为重量级锁,转重量级锁解锁流程
发生锁膨胀时MarkWord记录在哪?
锁膨胀
- 当线程1进行加轻量时,线程0已经加好了轻量
- 进入锁膨胀
- 为对象申请Monitor锁,对象头MarkWord指向Monitor地址
- 线程1进入Monitor的EntryList,进入BLOCKED状态
- 此时Owner是?如果此时第三个线程进入,它根据什么判断对象是否已加锁?
- 线程0解轻量失败。按地址找到Monitor,设置Owner为null,唤醒EntryList
- MarkWord信息呢?
偏向锁
持轻量锁线程每次进入临界区都需要做一次检查锁对象头,加一个锁记录,浪费性能。
当共享资源基本只有一个线程在使用,可以对其加偏向锁。
如果此时发生竞争,升级为轻量级锁
具体优化:第一次持锁将线程ID写入对象头MarkWord,后续发现ID是自己的就表示没有竞争
一个对象创建时:
- 如果开启了偏向锁(默认),markword后三位为101,thread、epoch、age为0
- 偏向锁默认是延迟的,不会在程序启动时立即生效,可使用VM参数
-XX:BiasedLockingStartupDelay=0禁用延迟 - 如果没有开启偏向锁,对象创建后,markword后三位为001,hashcode、age都为0,第一次用到hashcode时才会对其赋值
延迟的意义是什么?
禁用偏向锁 -XX:-UseBiasedLocking
可偏向的对象调用hashcode后,为了留出位置给hashcode,该对象的偏向会被禁用
已经加偏向锁的对象调用hashcode会发生什么?偏向锁转为重量锁?
调用wait/notify也会导致升级为重量级锁
自旋优化(多核CPU)
线程发现对象已锁,尝试做几次空循环,如果持锁线程退出临界区, 释放了锁,当前线程就可以避免进入阻塞态
批量重偏向
由于一个线程的加锁,导致撤销偏向锁的数量达到20阈值,对于余下偏向锁不升级,转而更为该线程的偏向锁
例:现有30个对象,偏向锁偏于线程1;线程1全部解锁后,线程2一次对这些对象加锁;前20个对象,偏向锁撤销,改为不可偏向状态;后10个对象,转偏向于线程2。
撤销批量重偏向
一个类下的对象实例,偏向撤销的次数超过40次,后续该类产生的新对象皆为不可偏向
锁消除
JIT 即时编译器 优化热点代码
如果发现一个锁对象不可能逃离方法、不可能被共享(逃逸分析),即消除synchronized代码
wait / notify
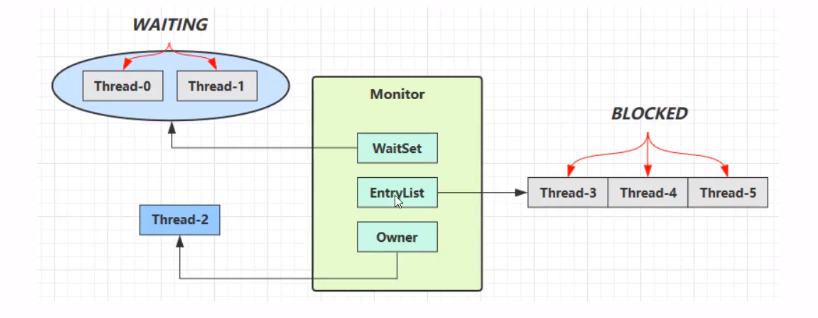
- Owner线程发现条件不满足,调用wait方法,进入WaitSet变为WAITING状态
- BLOCKED和WAITING的线程都处于阻塞状态,不占用CPU时间
- BLOCKED线程会在Owner线程释放锁时唤醒
- WAITING线程会在Owner线程调用notify或notifyAll时唤醒
- 被唤醒的线程重新竞争
API介绍
调用这些方法的前提是,线程已经获得了这个obj锁(结合synchronized)
obj.wait()让owner到WaitSet中等待obj.notify(),monitor从waitSet中随机挑一个唤醒obj.notifyAll()monitor唤醒所有waitSet中线程
sleep & wait 区别
sleep是Thread方法,wait是Object方法sleep不需要强制和synchronized配合使用,但wait需要和synchronized一起使用sleep不会释放对象锁,wait会
虚假唤醒
有多个线程使用wait等待不同的资源,其中一个资源准备好后使用notify却唤醒了错误的线程,称为虚假唤醒。
线程中使用while循环等待资源的语句,以防止虚假唤醒
synchronized(lock){
while(条件不成立){
lock.wait()
}
// 条件成立,干活
}
// 另一个线程,资源准备
synchronized(lock){
lock.notifyAll();
}
同步模式-保护性暂停(Guarded Suspension)
用在一个线程等待另一个线程的执行结果
- 有一个结果需要从一个线程传递到另一个线程,让他们关联同一个GuardedObject
- 如果有结果不断从一个线程到另一个线程那么可以使用消息队列(生产者/消费者)
- JDK中,jion的实现、Future的实现,均采用这种模式
- 因为要等待另一方的结果,因此归类到同步模式
Thread-1 ---> wait ---> GuardedObject <--- write <--- Thead-2
class GuardedObject {
private Object response;
public Object getResponse() throws InterruptedException {
return getResponse(0);
}
public synchronized Object getResponse(long timeout) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException();
}
if (timeout != 0) {
// 等待开始时间
long begin = System.currentTimeMillis();
long passed = 0;
// 没有结果
while (response == null) {
long waitTime = timeout - passed;
if (waitTime <= 0) {
// 等待超时
break;
}
this.wait(waitTime); // 避免虚假唤醒时,再次等待的时时间变长
// 经历时间
passed = System.currentTimeMillis() - begin;
}
} else {
while (response == null) {
this.wait();
}
}
return response;
}
public void setResponse(Object response) {
synchronized (this) {
// 产生结果
this.response = response;
this.notifyAll();
}
}
}
// 解耦内容产生者和内容消费者
class GuardedObjectHandler {
private static Map<Integer, GuardedObjectV2> boxes = new ConcurrentHashMap<>();
private static int id = 1;
private static synchronized int generateId() {
return id++;
}
public static GuardedObjectV2 newBox() {
GuardedObjectV2 guardedObjectV2 = new GuardedObjectV2(generateId());
boxes.put(guardedObjectV2.getId(), guardedObjectV2);
return guardedObjectV2;
}
public static GuardedObjectV2 getBox(int id){
return boxes.remove(id);
}
public static Set<Integer> ids(){
return boxes.keySet();
}
}
异步模式-生产者/消费者
- 与保护性暂停中的GuardedObject不同,不需要产生结果和消费结果的线程一一对应
- 消费队列可以用来平衡生产和消费的线程资源
- 生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据
- 消息队列是有容量限制的,满时不再加入,空时不再消耗
- JDK中各种阻塞队列,采用的这种模式
异步:数据不会被立刻消费
class MessageQueue{
private final LinkedList<Message> queue = new LinkedList<>();
private final int capacity;
public MessageQueue(int capacity) {
this.capacity = capacity;
}
public Message get() throws InterruptedException {
synchronized (queue){
while(queue.isEmpty()){
queue.wait();
}
Message message = queue.removeFirst();
queue.notifyAll();
return message;
}
}
public void put(Message message) throws InterruptedException {
synchronized (queue){
while(queue.size() == capacity){
queue.wait();
}
queue.addLast(message);
queue.notifyAll();
}
}
}
@Data
class Message{
private int id;
private Object value;
}
park & unpark
使用
//暂停当前线程
LockSupport.park();
// 恢复某个线程的运行
LockSupport.unpark(已暂停的线程对象);
park & unpark 以线程为单位来阻塞和唤醒线程
如果unpark在park前就被调用,则park不会暂停当前的线程
原理
每个Thead都会关联一个Parker对象
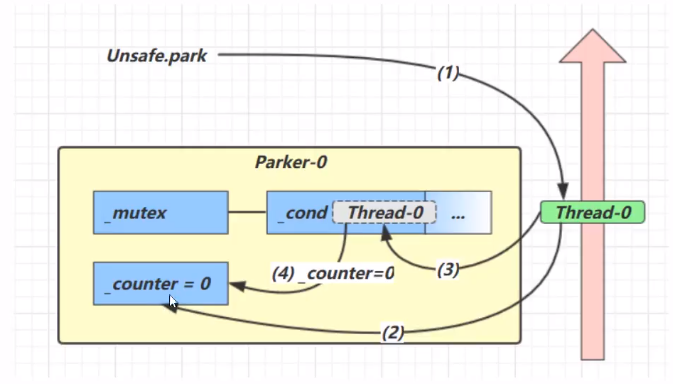
- 当前线程调用park方法
- 检查counter,为0,获得mutex互斥锁
- 线程进入cond条件变量阻塞
- 设置counter=0
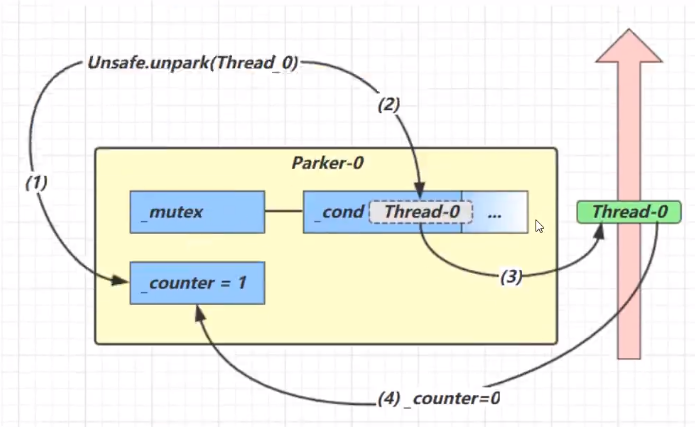
- 当前线程调用unpark,设置conter为1
- 唤醒cond条件变量的Thread-0
- Thread-0恢复运行
- 设置counter为0
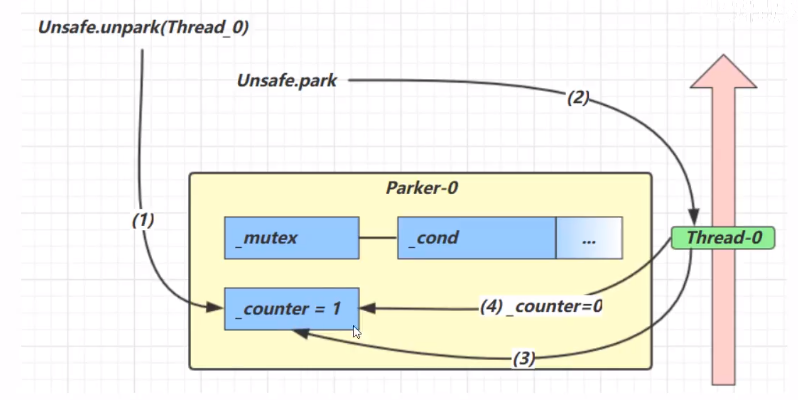
- 调用unpark,设置counter=1
- 调用park
- 检查counter发现为1,继续运行
- 设置counter为0
锁粒度
提出
一个类拥有多个功能,多个线程调用类对象不同的功能,且都对该对象上锁,那么相当于串行,并发效率低
解决
为无关联功能准备单独的锁对象
活跃性
死锁
- 互斥:每个资源每次只能被一个线程使用
- 请求与保持:线程因请求资源而阻塞时,对已获得的资源保持不放
- 不剥夺:线程获得的资源在未使用完毕前不被强行剥夺
- 循环等待:若干线程之间形成循环等待资源
活锁
线程没有被阻塞,但是由于某个状态没有达到,而不断运行的过程
比如一个线程++,一个线程–
通常的做法是在线程中增加随机睡眠时间
饥饿
一个线程始终得不到CPU调度执行,就不能结束
tip:在使用顺序加锁解决死锁的方法中,容易产生饥饿
ReentrantLock - 可重入锁
相比synchronized
- 可中断
- 可以设置超时时间
- 可以设置为公平锁
- 支持多个条件变量(等待不同资源进入不同的entrySet?)
与synchronized一样支持可重入
语法
try {
// 获得锁
reentrantLock.lock();
// 临界区
} finally {
// 释放锁
reentrantLock.unlock();
}
可重入
对于不可重入锁,即使是获得锁的线程,第二次进入锁时会被自己拦住
lockInterruptibly() - 可打断锁
竞争锁失败在等待时,可被调用interrupt()结束等待状态,进入catch句块
tryLock() - 可超时锁
不带参数,立刻返回获取结果
带参数,等待一段时间返回获取结果
可打断
如何实现的一段时间内持续尝试获得锁?保护性暂停
公平锁
默认为不公平锁,所有人竞争
公平锁,按照进入阻塞队列的顺序,先入先得
降低了并发度
多个条件变量
synchronized中也有条件变量,即waitSet,调用wait()进入waitSet等待
创建 Condition condition = lock.newCondition();
进入等待 condition.await(); //前提是拥有锁
通知唤醒 condition.signal(); //signalAll()
唤醒后重新参与竞争锁
循环顺序打印abc
wait & notify
static void fun1() {
WaitNotify n = new WaitNotify(1, 5);
new Thread(() -> n.print("a", 1, 2)).start();
new Thread(() -> n.print("b", 2, 3)).start();
new Thread(() -> n.print("c", 3, 1)).start();
}
@Slf4j
class WaitNotify {
private final int loopNumber;
private int flag;
WaitNotify(int flag, int loopNumber) {
this.loopNumber = loopNumber;
this.flag = flag;
}
public void print(String content, int exceptedFlag, int nextFlag) {
for (int i = 0; i < loopNumber; i++) {
synchronized (this) {
while (flag != exceptedFlag) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.info(content);
flag = nextFlag;
notifyAll();
}
}
}
}
await & signal
static void fun2() {
AwaitSignal awaitSignal = new AwaitSignal(5);
Condition a = awaitSignal.newCondition();
Condition b = awaitSignal.newCondition();
Condition c = awaitSignal.newCondition();
new Thread(() -> awaitSignal.print("a", a, b)).start();
new Thread(() -> awaitSignal.print("b", b, c)).start();
new Thread(() -> awaitSignal.print("c", c, a)).start();
try {
awaitSignal.lock();
a.signal();
} finally {
awaitSignal.unlock();
}
}
@Slf4j
class AwaitSignal extends ReentrantLock {
private final int loopNumber;
AwaitSignal(int loopNumber) {
this.loopNumber = loopNumber;
}
public void print(String content, Condition excepted, Condition next) {
for (int i = 0; i < loopNumber; i++) {
try {
lock();
excepted.await();
log.info(content);
next.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
unlock();
}
}
}
}
park & unpark
static Thread t1, t2, t3;
static void fun3(){
ParkUnpark parkUnpark = new ParkUnpark(5);
t1 = new Thread(()->parkUnpark.print("a", t2));
t2 = new Thread(()->parkUnpark.print("b", t3));
t3 = new Thread(()->parkUnpark.print("c", t1));
t1.start();
t2.start();
t3.start();
LockSupport.unpark(t1);
}
@Slf4j
class ParkUnpark {
private final int loopNumber;
ParkUnpark(int loopNumber) {
this.loopNumber = loopNumber;
}
public void print(String content, Thread next){
for (int i=0; i<loopNumber; i++){
LockSupport.park();
log.info(content);
LockSupport.unpark(next);
}
}
}
共享模型-内存(JMM)
上一章Monitor主要关注访问共享变量时,保证临界区内代码的原子性
这里描述共享变量在多线程之间的可见性,与多条指令执行时的有序性
Java内存模型(JMM)
从java层面,定义了主存和工作内存抽象概念,底层对应着CPU寄存器、缓存、硬件内存、CPU指令优化等。
主存:所有线程都共享的数据 共享变量
工作内存:每个线程私有的数据 局部变量
JMM体现在以下几个方面
- 原子性-保证指令不会受到线程上下文切换的影响
- 可见性-保证指令不会受到cpu缓存的影响
- 有序性-保证指令不会受到cpu指令并行优化的影响
可见性
案例-退不出的循环
static boolean run = true;
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (run) {
// do somethings
}
});
t.start();
sleep(1000);
log.info("尝试停止");
run = false;
}
分析:
- 初始状态,t线程从主存中读取run的值到工作内存
- 因为t线程要频繁从主存读取,JIT将run的值缓存到自己工作内存的高速缓存中,减少对主存的访问
解决:
run加关键字volatile,声明为易变,每次都从主存中读取
避免线程从自己的工作内存中查找变量的值,线程操作变量都是修改主存中的值
synchronized也可保证变量的可见性
适合一个线程修改,多个线程读取的情况
结合Volatile的两阶段终止模式
@Slf4j
class TwoPhaseTermination {
private Thread monitorThread;
private volatile boolean terminated = false;
public void start(){
monitorThread = new Thread(()->{
while(true){
if (terminated){
// 处理后事
log.info("处理后事");
break;
}
try {
TimeUnit.SECONDS.sleep(2);
// 监控
log.info("监控状态");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "monitor");
monitorThread.start();
}
public void stop(){
terminated = true;
monitorThread.interrupt();
}
}
有序性
JVM会在不影响正确性的前提下,调整语句的执行顺序
static int i;
static int j;
// 在某一个线程内执行复制操作
i = ...;
j = ...;
可见,i和j的先后顺序对结果不会产生影响,所以上述代码执行时两种顺序都有可能
这种特性称为指令重排,多线程下指令重排会影响正确性。
指令重排序优化
CPU被设计为一个时钟周期完成一条执行时间最长的指令。
指令还可以再划分成一个个更小的阶段,例如:取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回

现代CPU支持多级指令流水线,例如支持同时执行取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回的处理器称为五级指令流水线。这时CPU可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,本质上,刘姝贤技术并不能缩短单条指令的执行时间,但变相地提高了指令的吞吐率
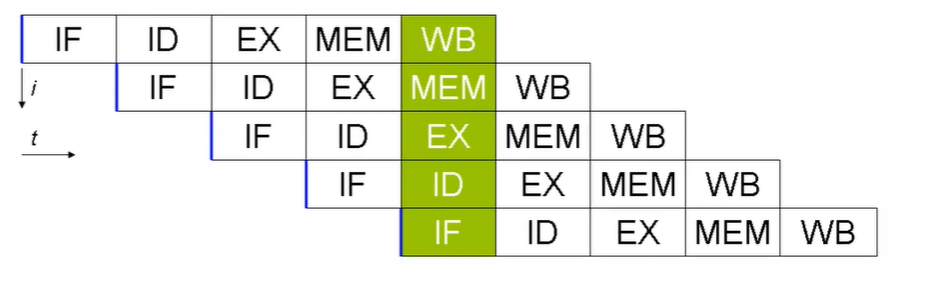
在不改变程序结果的前提下, 这些指令的各个阶段可以通过重排序和组合来实现指令级并行
指令重排的前提是,重排后不影响结果,如
// 可以重排
int a = 10;
int b = 10;
sout( a + b );
// 不能重排
int a = 10;
int b = a - 5;
诡异的结果
int num = 0;
boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r){
if( ready ) {
r.res = num + num
} else {
r.res = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r){
num = 2;
ready = true;
}
在发生指令重排的情况下,可能ready先置为true,从而得到r.res=0
解决
volatile能防止之前的变量被重排序
Volatile原理
Volatile的底层实现原理是内存屏障,Memory Barrier
- 对volatile变量的写指令后,会加入写屏障
- 对volatile变量的读指令前,会加入读屏障
如何保证可见性
-
写屏障,保证在该屏障之前的,对共享变量的改动,都同步到主存当中
-
volatile boolean ready = false; public void actor2(I_Result r){ num = 2; ready = true; // 写屏障,上面所有的赋值都同步到主存 } -
读屏障,保证改屏障之后,对共享变量的读取,加载的是主存中的最新数据
-
public void actor1(I_Result r){ // 读屏障,下面所有的读取都是读主存 if( ready ) { r.res = num + num } else { r.res = 1; } }
如何保证有序性
- 写屏障,之前的代码不会指令重排到屏障后面
- 读屏障,之后的代码不会指令重排到屏障前面
总结
不会改变volatile变量指令的位置
不能解决指令交错,即不保证原子性
double-checked locking 问题
以double-checked locking单例模式为例
public final class Singleton{
private Singleton() {}
private static Singleton INSTANCE = null;
public static Singleton getInstance() {
if (INSTANCE == null) {
// 之前的访问会同步,之后的访问无需锁
synchronized (Singleton.class){
// 防止已经有其他线程在等待锁
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
INSTANCE = new Singleton();在字节码级别发生指令重排,正常来说是先调用构造函数,再赋值引用给INSTANCE,此时由于指令重排发生了颠倒- 在调用构造函数指令之前,另一个线程获得时间片,进入第一个
if (ISNTANCE == null ),此时由于INSTANCE已经获得了引用,语句跳转到return,线程开始使用INSTANCE - 由于使用发生在了调用构造函数之前,程序出错
这里之所以发生了有序性问题,是由于INSTANCE出现在了同步代 码块之外。完全处于同步内的变量不会发生有序性问题
double-checked locking 解决
volatile
happens-before 规则
如何保证对共享变量的写操作对其它线程的写操作可见?
- 放在同一个锁下
volatile- 线程
start()前的写,对start()后的读可见 - 线程结束前的写,对结束后的读可见
- 线程t1打断t2前的写,对其它线程得知t2被打断后的读可见
- 对变量默认值(
0、false、null)的写,对其它线程的读可见 - 写屏障之前的代码,对其它线程可见
共享模型-无锁
CAS与volatile
AtomicInteger balance = new AtomicInteger(amount);
// 无锁保证线程安全
private int withdraw(int amount){
while(true) {
int prev = balance.get();
int next = prev - amount;
if(balance.compareAndSet(prev, next)) // CAS 比较并设置
break;
}
}
其中的关键是compareAndSet,必须是原子操作;
不断尝试,始终拿到最新的值去比较prev,直到成功
因此AtomicInteger内部的值使用volatile修饰的
无锁情况下,多线程保持运行需要多核CPU支持,否则仍会发生上下文切换
CAS特点
结合CAS和volatile可以实现无锁并发, 适用于线程少、多核CPU场景
- CAS是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算修改也不过是再重试
- synchronized是基于悲观锁的思想:最悲观的估计,得防止其他线程来修改共享变量
- CAS体现的是无锁并发、无阻塞并发。
- 因为没有使用synchronized,所以线程不会陷入阻塞,这是效率提升的原因之一
- 但如果竞争激烈,重试必然频繁发生,反而效率会影响
原子整数
- AtomicBoolean
- AtomicInteger
- AtomicLong
AtomicInteger i = new AtomicInteger(5);
i.updateAndGet(x -> x * 10);
原子引用
- AtomicReference
- AtomicMarkableReference
- AtomicStampedReference
AtomicReference无法感知到共享变量是否经历了修改,例如A改成B又改回来
如果希望只要有其他线程改动过共享变量,那么自己的cas就算失败,这时,仅比较值是不够的的,需要再加一个版本号。AtomicStampedReference
如果不关心更改了几次,只关心有没有改过。AtomicStampedReference
原子数组
要保护的不是引用本身,而是引用内的元素
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
字段更新器
要保护的不是引用本身,而是引用内的字段
- AtomicReferenceFiledUpdater
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdater
原子累加器
jdk1.8提供了专门用来做原子累加的类LongAdder等,性能较高
之前提到的AtomicLong也可做原子累加
关于性能提升:存在竞争时设置多个累加单元,最后将结果汇总,这样就减少了CAS重试词素
原理略
Unsafe
操作内存、线程;
CAS相关:通过内存偏移量进行一些底层的CAS操作
共享模型-不可变
日期转换的问题
提出
SimpleDateFormat不是线程安全的,同一个对象在被多个线程共享使用时,很容易出异常或是解析错误
解决
不可变实现: DateTimeFormatter
不可变设计
String类是不可变的,以此为例
public final class String implements ... {
private final char value[];
private int hash;
// ...
}
final的使用
- 对于属性,确保只读不能修改
- 对于类,防止被继承破坏不可变性
保护性拷贝
构造新的字符串对象时,生成新的value[],对内容进行复制。这种通过创建副本对象来避免共享的手段诚挚为保护性拷贝
设计模式-享元模式
定义:Flyweight pattern,当需要重用数量有限的同一类对象时
A flyweight is an object that minimizes memory usage by sharing as much data as possible with other similar objects
包装类
Boolean、Byte等包装类提供了valueOf方法;
例如Long的valueOf会缓存-128~127之间的Long对象,在这个范围之间会重用对象,大于这个范围,才会创建新的Long对象
DIY
案例:一个线上商城应用,如果每次都重新创建和关闭数据库连接,性能会受到极大影响,这时预先创建好了一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再放回连接池。这样既节约了创建和关闭的时间,也实现了连接的重用。
class Pool {
private int poolSize;
private Connection[] conns;
// 标记连接是否占用
private AtomicReferenceArray<Boolean> busy;
public Pool(int poolSize) {
this.poolSize = poolSize;
this.conns = new Connection[poolSize];
this.busy = new AtomicReferenceArray<>(new Boolean[poolSize]);
for (int i = 0; i < poolSize; i++) {
conns[i] = new MockConnection();
}
}
// 借连接
public Connection borrow() {
while (true) {
for (int i=0; i<poolSize; i++){
if (!busy.get(i)){
busy.compareAndSet(i, false, true);
return conns[i];
}
}
// 如果没有空闲连接
synchronized (this){
try{
wait();
} catch (InterruptedException e){
e.printStackTrace();
}
}
}
}
// 还连接
public void free(Connection conn) {
for (int i=0; i<poolSize; i++){
if (conns[i] == conn){
// 此处不会发生竞争
busy.set(i, false);
synchronized (this){
notifyAll();
}
}
}
}
}
final原理
语句之后加入写屏障;
其余略
线程工具
异步模式 - 工作线程
定义
让有限的工作线程(worker thread)来轮流异步处理无限多的任务。也可将其归类为分工模式。典型的实现就是线程池,也体现了经典设计模式中的享元模式
不同类型的任务应该使用不同的线程池,避免饥饿,提升效率
饥饿
固定大小线程池会有饥饿现象,如果任务需要等待其他任务产生的结果,但由于线程数不足,导致无法继续运行下去
解决就是分开使用不同的线程池
创建多少线程合适?
- 过小会导致程序不能充分地利用系统资源、容易导致饥饿
- 过大会导致更多的线程上下文切换,占用更多内存
CPU密集型运算
通常采用cpu核数 + 1能够实现最优的cpu利用率,+1是保证当前线程由于缺页中断或其他原因导致暂停时,额外的这个线程就能顶上去,保证CPU时钟周期不被浪费
IO密集型运算
CPU不总是处于繁忙状态。经验公式如下
线程数 = 核数 * 期望CPU利用率 * 总时间(cpu计算时间+等待时间) / CPU计算时间
例如4核CPU计算时间是50%,其他等待时间是50%,期望100%利用,套用得
` 4 * 1 * 1 / 0.5 = 8`
自定义线程池
- 减少线程数量,避免频繁的上线文切换
- 重用已有的线程资源
@Slf4j
public class TestPool {
public static void main(String[] args) throws InterruptedException {
ThreadPool threadPool = new ThreadPool(1, 1, 1000, TimeUnit.MILLISECONDS,
// 1. 死等
// BlockingQueue::put
// 2. 带超时等待放入
// (queue, task) -> queue.put(task, 1500, TimeUnit.MILLISECONDS)
// 3. 放弃任务执行
// (queue, task) -> log.info("放弃执行")
// 4. 抛出异常
// (queue, task) -> {throw new RuntimeException("任务加入队列超时异常");}
// 5. 主线程自己执行
(queue, task) -> task.run()
);
for (int i=0; i<3; i++){
final int j = i;
threadPool.execute(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("Task - {} 执行完毕.", j);
});
}
}
}
@Slf4j
class ThreadPool {
// 任务队列
private BlockingQueue<Runnable> taskQueue;
// 线程集合
private final HashSet<Worker> workers = new HashSet<>();
// 最大线程个数
private int coreSize;
// 一个线程获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
// 拒绝策略
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int coreSize, int blockingTaskSize, long timeout, TimeUnit timeUnit,
RejectPolicy<Runnable> rejectPolicy) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.rejectPolicy = rejectPolicy;
this.taskQueue = new BlockingQueue<>(blockingTaskSize);
}
// 执行任务
public void execute(Runnable task) {
// 当任务数没有超过 coreSize 时,直接交给 worker 执行
// 否则加入任务队列保存起来
synchronized (workers) {
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
workers.add(worker);
worker.start();
} else {
// taskQueue.put(task);
// 如果满 选择拒绝策略
taskQueue.tryPut(rejectPolicy, task);
}
}
}
class Worker extends Thread {
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 执行任务
// 当 task 不为空,执行任务
// 当 task 执行完毕,再接着从任务队列获取人物并执行
while (task != null || (task = taskQueue.take(timeout, timeUnit)) != null) {
try {
log.info("任务执行...");
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
task = null;
}
}
log.info("该线程没有更多的任务,将结束");
synchronized (workers) {
workers.remove(this);
}
}
}
}
@Slf4j
class BlockingQueue<T> {
// 任务队列
private Deque<T> queue = new ArrayDeque<>();
// 锁
private final ReentrantLock lock = new ReentrantLock();
// 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
// 容量
private int capaticy;
public BlockingQueue(int capaticy) {
this.capaticy = capaticy;
}
// 阻塞获取
public T take() {
try {
lock.lock();
while (queue.isEmpty()) {
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
// 带超时的阻塞获取
public T take(long timeout, TimeUnit unit) {
long remain = unit.toNanos(timeout);
try {
lock.lock();
while (queue.isEmpty()) {
try {
if (remain <= 0){
log.info("阻塞获取超时");
return null;
}
remain = emptyWaitSet.awaitNanos(remain);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
fullWaitSet.signal();
return t;
} finally {
lock.unlock();
}
}
//阻塞添加
public void put(T element) {
try {
lock.lock();
while (queue.size() == capaticy) {
try {
log.info("阻塞添加");
fullWaitSet.await();
log.info("阻塞添加成功");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
queue.addLast(element);
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
// 带超时的阻塞添加
public boolean put(T element, long timeout, TimeUnit timeUnit) {
long remain = timeUnit.toNanos(timeout);
try {
lock.lock();
while (queue.size() == capaticy) {
try {
if (remain <= 0) {
// 添加失败
return false;
}
remain = fullWaitSet.awaitNanos(remain);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
queue.addLast(element);
emptyWaitSet.signal();
return true;
} finally {
lock.unlock();
}
}
public void tryPut(RejectPolicy<T> rejectPolicy, T element) {
try {
lock.lock();
if (queue.size() == capaticy) {
rejectPolicy.reject(this, element);
} else {
queue.addLast(element);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
}
@FunctionalInterface
interface RejectPolicy<T> {
void reject(BlockingQueue<T> blockingQueue, T element);
}
Java-ThreadPoolExecutor
线程池状态
ThreadPoolExecutor 使用 int 的高3位来表示线程池状态,低29位表示线程数量
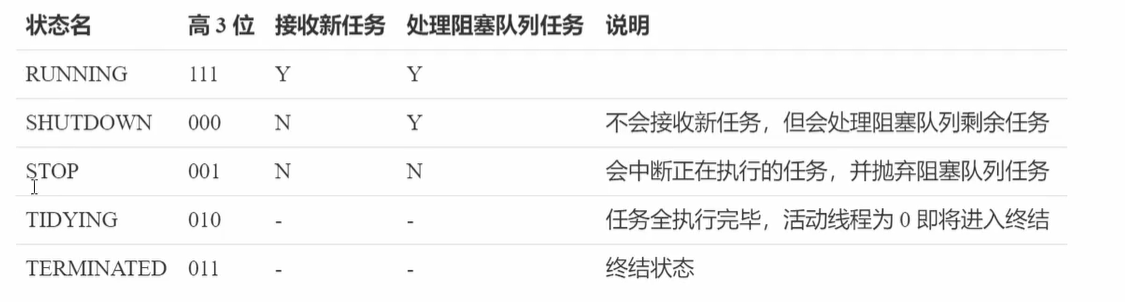
从数字上比较,terminated > tidying > stop > shutdown > running
状态信息与数量信息存在一个变量中,目的是保证修改操作只需一次cas
构造方法
public ThreadPoolExecutor(int corePoolSize, // 核心线程数(最多保留的线程数量)
int maximumPoolSize, // 最大线程数目
long keepAliveTime, // 生存时间 针对救急线程
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 线程工厂可以为线程创建时起个好名字
RejectedExecutionHandler handler // 拒绝策略
)
tip:核心线程数 + 救急线程数 = 最大线程数
-
如果选择了有界队列,当阻塞队列已满,新任务到达时,交由救急线程执行;执行完毕,生存时间到后移除;
-
线程到达maximumPoolSize,执行拒绝策略
- AbortPolicy,抛出RejectedExecutionException异常,这是默认策略
- CallerRunsPolicy,让调用者执行任务
- DiscardPolicy,放弃本次任务
- DiscardOldestPolicy,放弃队列中最早的任务,加入队列
- Dubbo实现, 抛出异常前记录日志,打印错误信息
- Netty实现,创建一个新的线程来执行任务
- ActiveMQ实现,超时等待尝试放入队列
- PinPoint实现,拒绝策略链
根据这个构造方法,JDK的Executors类中提供了众多工厂方法来创建各种用途的线程池
newFixedTreadPool

- 核心线程数 == 最大线程数,即不会创建救急线程
- 阻塞队列无界,即可放入任意数量任务
适用于任务量已知,相对耗时的任务
newCachedThreadPool

- 全都是救急线程(60s回收);可以无限创建
- SynchronousQueue特点,容量为0,有人取才能继续放;具体来说,put方法在放入后会阻塞住,直到有其他线程执行take,put方法才会结束,同理take也需等待put
为什么要用这种队列 ? -> 队列没有存储空间,且put和take互相阻塞,这意味着每有一个新的任务提交就必须要找到一个工作线程去处理,如果当前没有空闲线程,那么就会再创建一个新的线程
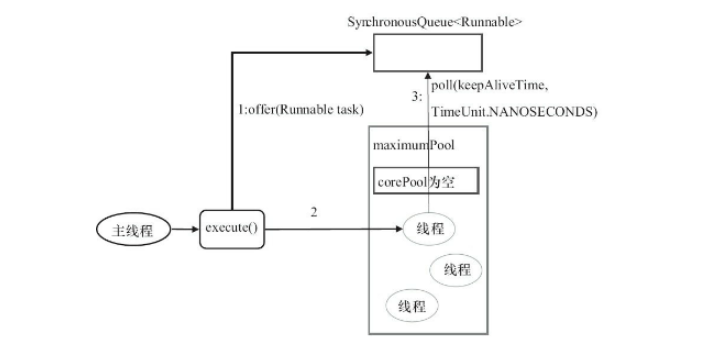
适用于任务数比较密集,耗时较短的情况
newSingleThreadExecutor
- 核心线程数量为1,没有救急线程
- 等待队列无限
适用于希望多个任务串行执行
与自己创建一个线程跑有什么区别?
- 自己创建的线程失败终止后没有补救措施,而线程池还会新建线程维持核心线程数量
与newFixedThreadPool(1)有什么区别?
- 首先,后者的线程数量可以修改,single始终是single
new FinalizableDelegatedExecutorService应用装饰器模式,只对外暴露ExecutorService接口,不能调用ThreadPoolExecutor(对接口的实现)中特有的方法- 后者暴露
ThreadPoolExecutor对象,可以强转后调用setCorePoolSize等方法修改
提交任务

- invokeAll 要等待所有任务完成,结果顺序同任务顺序
停止线程池
shutdown()将状态改为SHUTDOWN,进行中的任务和队列中的任务继续执行,不会阻塞主线程awaitTermination(...)阻塞至所有任务执行完shutdownNow()将状态改为STOP,打断进行中的任务,返回队列中的任务
ScheduledExecutorService
创建线程池Excutors.newScheduledExecutorService(int corePoolSize)
设置延时任务schedule(Runnable runnable, long delay, TimeUnit unit)
设置延时周期任务,从上一个任务开始计算周期 scheduleAtFixedRate(Runnable runnable, long delay, long period, TimeUnit unit)
设置延时周期任务,从上一个任务结束计算周期scheduleWithFixedDelay(Runnable runnable, long delay, long period, TimeUnit unit)
异常处理
- 默认情况下,对异常不会有反应
- 用try-catch在任务内处理
- Future调用get方法,如果有异常会打印异常信息
Tomcat线程池
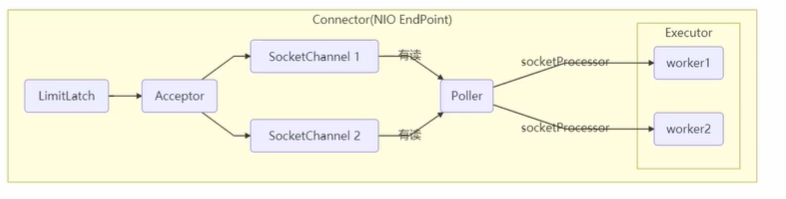
- LimitLatch用来限流,控制最大连接个数
- Acceptor负责【接收新的socket连接】
- Poller负责监听socket channel是否有【可读的I/O事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给Executor线程池处理
- Executor线程池中的工作线程负责【处理请求】
Tomcat线程池,当队列满时会进行一次超时尝试,再满则抛出异常
Fork/Join线程池
JDK1.7引入,体现一种分治思想,适用于能够进行任务拆分的cpu密集型运算
所谓任务拆分,是将一个大任务拆分为算法上相同的小任务。
Fork/Join把每个任务的分解和合并交给不同的线程完成;默认创建与cpu核心数大小相同的线程池
提交给Fork/Join线程池的任务需要继承RecursiveTask或RecursiveAction,下例展示对1~n整数求和的任务
psvm{
ForkJoinPool pool = new ForkJionPool(..){
sout(pool.invoke(new AddTask(100)));
}
}
class AddTask extends RecursiveTask<Integer> {
/**
* 拆分策略1:AddTask(5) = 5 + AddTask(4)
*/
int n;
public AddTask(int n){this.n = n;}
@Override
public Integer compute(){
if (n == 1){
return 1;
}
AddTask subTask = new AddTask(n - 1);
// 让一个线程去执行此任务
subTask.fork();
return n + subTask.join();
}
/**
* 拆分策略2:AddTask(1, 100) = AddTask(1, 50) + AddTask(51, 100)
*/
}
并行递归?
J.U.C - Java Util Concurrent
AQS
概述
AbstractQueuedSynchronizer,阻塞式锁和相关的同步器工具的框架
特点:
- 用state属性来表示资源的状态(独占和共享),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- compareAndSetState - cas机制设置state状态
- 独占式表示只有一个线程能够访问资源
- 提供了先进先出的等待队列,类似于Monitor的EntryList
- 条件变量(Condition)来实现等待、唤醒机制,支持多个条件变量,类似于Monitor的WaitSet
tip:Monitor是用c++实现的
子类主要实现这样一些方法:
- tryAcquire
- tryRelease
- tryAcquireShared
- tryReleaseShared
- isHeldExclusively
使用:
获取锁
// 如果获取锁失败
if (!tryAcquire(arg)) {
// 入队,可以选择阻塞当前线程 LockSupport
}
释放锁
// 如果释放锁成功
if (tryRelease(arg)) {
// 让阻塞的线程恢复运行
}
自定义实现(不可重入)
@Slf4j
public class TestAQS {
public static void main(String[] args) {
MyLock lock = new MyLock();
new Thread(() -> {
try {
lock.lock();
log.info("线程1获得锁");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("线程1释放锁");
lock.unlock();
}
}).start();
new Thread(() -> {
try {
lock.lock();
log.info("线程2获得锁");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("线程2释放锁");
lock.unlock();
}
}).start();
}
}
class MyLock implements Lock {
/**
* 独占锁 同步器类
*/
static class MySync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if (compareAndSetState(0, 1)) {
// 加锁成功,设置owner为当前线程
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
setExclusiveOwnerThread(null);
// state是volatile的,用写屏障防止之前的语句重排序,保证对其它线程可见
setState(0);
return true;
}
/**
* 是否持有独占锁
*/
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
public Condition newCondition() {
return new ConditionObject();
}
}
private MySync sync = new MySync();
/**
* 加锁,否则进入的等待队列
*/
@Override
public void lock() {
// tryAcquire,不成功进入等待队列
sync.acquire(1);
}
/**
* 加锁,可打断
*/
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
/**
* 尝试加锁,一次
*/
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
/**
* 尝试加锁,带超时
*/
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(time));
}
/**
* 解锁
*/
@Override
public void unlock() {
// tryRelease并唤醒正在阻塞的线程
sync.release(1);
}
@Override
public Condition newCondition() {
return sync.newCondition();
}
}
ReentrantLock原理
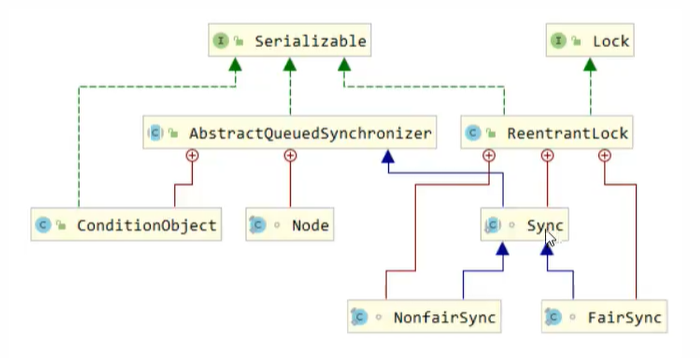
非公平锁实现
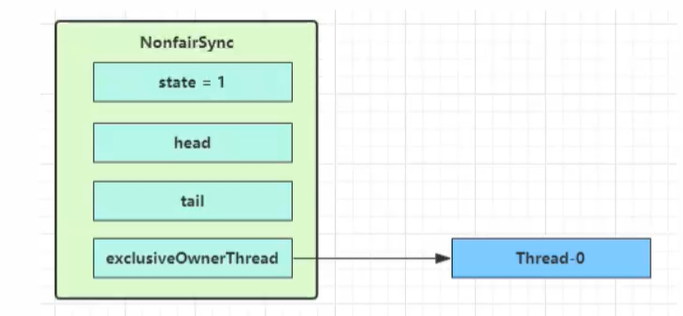
ReentrantLock默认为非公平锁,NonfairSync继承自AQS
没有竞争时
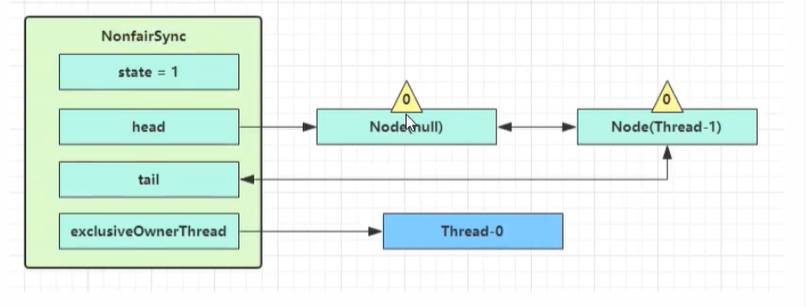
第一个竞争出现时(竞争失败例)
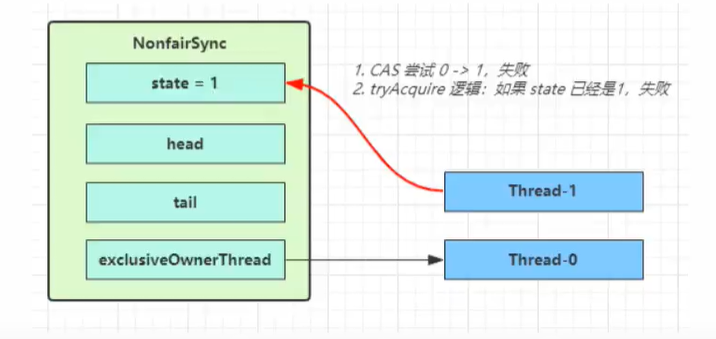
Thread-1执行了
- CAS尝试将state从0改为1,结果失败
- 进入tryAcquire(),state已经是1,结果失败
- 进入addWaiter(),构造Node队列
- 图中黄色三角表示该Node的waitStatus状态,0为正常状态
- Node的创建时懒惰的
- 其中第一个Node称为Dummy(哑元),用来占位
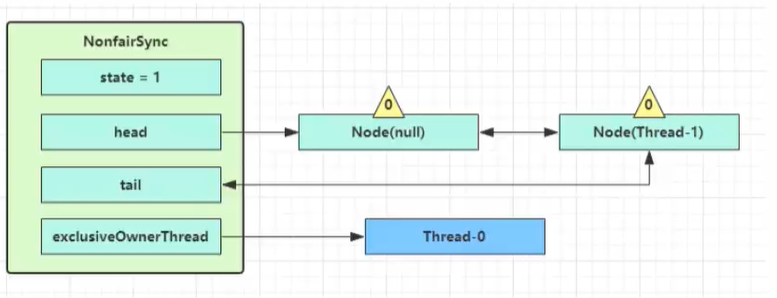
- 进入acquireQueued(),在死循环中不断尝试获得锁,失败后进入park()阻塞
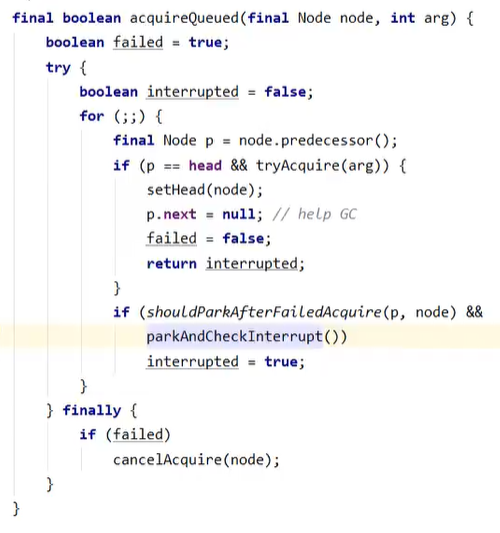
- 如果前驱节点是head(哑元?),那么再次tryAcquire(),state仍为1,失败
- 否则进入shouldParkAfterFailedAcquire(),将前驱node的waitStatus改为-1(表示该节点有责任唤醒后继节点),这次返回false
- 再次循环进入shouldParkAfterFailedAcquire(),由于waitStatus已为-1,则返回true
- 进入parkAndCheckInterrupt(),即park状态
麻了,后面没看进去
读写锁
ReentrantReadWriteLock
当读操作远远高于写操作时,使用读写锁让读之间并发,提高性能
提供一个数据容器类内部分别使用读锁保护数据的read()方法,写锁保护数据的write()方法
@Slf4j
class DataContainer {
private Object data;
private ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
private ReentrantReadWriteLock.ReadLock r = rw.readLock();
private ReentrantReadWriteLock.WriteLock w = rw.writeLock();
public Object read() {
try {
r.lock();
log.info("got read lock");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return data;
} finally {
log.info("releasing read lock");
r.unlock();
}
}
public void write(Object obj) {
try {
w.lock();
log.info("got write lock");
} finally {
log.info("releasing write lock");
w.unlock();
}
}
}
读写、写写之间互斥,读读之间并行
注意事项
- 读锁不支持条件变量。因为读操作是并行的,写操作不需要读锁?
- 重入时升级不支持:即持有读锁的情况下去获取写锁,会导致获取写锁永久等待
- 重入时降级支持:即持有写锁的情况下去获取读锁
应用场景之数据缓存 略
ReentrantReadWriteLock源码 略
StampedLock
为了进一步优化读性能,在使用读锁、写锁时都必须配合【戳】使用
// 读锁相关
long stamp = lock.readLock();
lock.unlockRead(stamp);
// 写锁相关
long stamp = lock.writeLock();
lock.unlockWrite(stamp);
乐观读,StampedLock支持tryOptimisticRead(),不加锁,读取完毕后需要做一次【戳校验】,如果校验通过,表明这期间没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。
long stamp = lock.tryOptimisticRead();
// 校验
if (!lock.validate(stamp)) {
// 锁升级
}
Semaphore - 信号量
用来限制同时访问共享资源的线程数量上限 - PV操作
public static void main(String[] args) {
int permits = 3;
Semaphore semaphore = new Semaphore(permits);
for (int i=0; i<10; i++){
new Thread(()->{
try {
semaphore.acquire();
log.info("running");
Thread.sleep(1000);
log.info("end...");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}, "t" + (i + 1)).start();
}
}
应用:
- 限流,限制线程数量
- 实现简单的数据库连接池,可比较先前的享元模式
// 借连接
public Connection borrow() {
try {
semaphore.acquire();
// 如果没有空闲连接, 在此等待
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < poolSize; i++) {
if (!busy.get(i)) {
busy.compareAndSet(i, false, true);
return conns[i];
}
}
// unreachable
return null;
}
// 还连接
public void free(Connection conn) {
for (int i = 0; i < poolSize; i++) {
if (conns[i] == conn) {
// 此处不会发生竞争
busy.set(i, false);
semaphore.release();
break;
}
}
}
原理略
CountdownLatch
用来进行线程同步协作,等待所有线程完成倒计时;其实还是PV操作
构造参数初始化倒计时,await()处等待技术归零,countDown()计数减1
CyclicBarrier
用来进行线程同步协作,等待线程满足某个计数。
构造参数初始化计数个数,每个线程执行到某个需要同步的时刻调用await()方法进行等待,当等待的线程数满足计数个数时,继续执行
参数二接收一个Runnable,用于传入等待满足后的动作
可重用,条件满足后计数恢复
与前者的区别在于,await()被多处调用,多处等待;而countdownLatch是一处
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(2);
CyclicBarrier barrier = new CyclicBarrier(2, ()->{
log.info("over.");
});
for (int i = 0; i < 3; i++) {
service.submit(()->{
log.info("task 1 begin.");
sleep(1000);
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
service.submit(()->{
log.info("task 2 begin.");
sleep(2000);
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
service.shutdown();
}
线程安全集合类
- 历史遗迹如Hashtable、Vector
- 装饰器模式,传入一个不安全的集合类,用synchronized修饰不安全的方法。如Collections.synchronizedCollection
- concurrent包下的集合类
- Blocking类,大部分实现基于锁,并提供用来阻塞的方法
- CopyOnWrite类,修改开销重
- Concurrent类
- 内部很多操作采用CAS,性能较好
- 弱一致性
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历(非安全容器执行fail-fast),这是内容是旧的
- 求大小弱一致性,size操作未必100%正确
- 读取弱一致性
ConcurrentHashMap原理 略
HashMap并发扩容死链(JDK1.7) 略
ConcurrentHashMap源码 略