[TOC]
Kubernetes
组件介绍
-
kubectl 命令行管理工具
- master
- api-server 一切服务访问的入口
- scheduler 任务调度器,分配任务,通过api-server将任务写入etcd,再由node接收执行
- replication controller 维护容器副本期望数量(Pod)
- node
- kubelet 操作CRI(container runtime interface),维持pod生命周期
- kube-proxy 操作IPTABLES、IPVS,实现服务映射访问
- pod
- container
- etcd 可信赖、分布式键值对数据库,保存集群需要持久化的信息
其他插件:
- CoreDNS 可以为集群中的svc创建一个DNS服务
- dashboard web-ui
- ingress controller 可以实现7层代理?官方只有4层?啥意思
- Federation 跨集群统一化管理
- Prometheus k8s集群监控
- elk 日志统一分析接入
基础概念
Pod
最小的封装集合(管理单位),一个Pod里会封装多个容器,共同组成node的运行环境
pod内必然会启动一个pause容器,其他容器会共用pause的网络栈、存储卷。可以理解为通过一个pause容器将Pod内的所有容器关联为”一个容器”。因此,同一个Pod里端口、文件不能冲突
服务发现
一个service拥有一些pod,并通过负载均衡算法向外反向代理
网络通讯方式
Kubernetes的网络模型假定所有Pod都在一个可以直接连通的扁平化网络空间中
- Pod内的container之间:localhost
- Pod与Pod之间:Overlay Network,方案:Flannel,集群内的所有pod拥有全局唯一的IP地址
- Pod与Service之间:LVS
- Pod到外网:发送数据包到宿主机网卡 balabala
- 外网到Pod:通过Service服务发现
资源清单 重要
K8s中的资源
- 名称空间级别:
kube-system、default - 集群级别:
role;不管在什么名称空间下定义,在其他空间中都能看到 - 元数据级别:
HPA
资源清单
- 必须存在的属性
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| version | string | api-server 的版本,基本上是v1,可以用kubectl api-versions查询 |
| kind | string | 该清单定义的资源类型和角色,比如:Pod |
| metadata.name | string | 元数据对象的名字,比如定义Pod的名字 |
| metadata.namespace | string | 元数据对象的命名空间 |
-
主要属性,部分不指定会默认 | 参数名 | 说明 | | ——————— | ———————————————————— | | spec.containers[].name | 定义容器的名字 | | spec.containers[].image | 要用到的镜像的名称 | | spec.containers[].imagePullPolicy | 镜像拉取策略:
Always每次都尝试重新拉取,默认Never仅适用本地镜像IfNotPresent本地有就本地,没有就拉取 | | spec.containers[].command[] | 指定容器启动命令 | | spec.containers[].args | 指定容器启动命令参数 | | spec.containers[].workingDir | 指定容器的工作目录 | | spec.containers[].volumeMounts[].name | 指定可被容器挂载的存储卷到的名称 | | spec.containers[].volumeMounts[].mountPath | 指定可被容器挂载的存储卷的路径 | | spec.containers[].volumeMounts[].readOnly | 读写模式truefalse| | spec.containers[].ports[].name | 指定端口名称 | | spec.containers[].ports[].containerPort | 指定容器需要监听的端口号 | | spec.containers[].ports[].hostPort | 指定主机暴露端口号 | | spec.containers[].ports[].protocol | 默认TCP、UDP| | spec.containers[].env[].name | 指定环境变量名称 | | spec.containers[].env[].value | 指定环境变量值 | | spec.containers[].resources.limits.cpu | 单位为core数 | | spec.containers[].resources.limits.memory | 内存限制,单位为M | | spec.containers[].resources.requests.cpu | CPU请求 | | spec.containers[].resources.requests.memory | 内存请求 | -
额外的参数项
| 参数名 | 说明 |
|---|---|
| spec.restartPolicy | Pod的重启策略:默认Always OnFailure Never |
| spec.nodeSelector | 定义Node的Label过滤标签,以k:v格式指定 |
| spec.imagePullSecrets | 定义pull镜像时使用的secret名称,以name:secretkey格式指定 |
| spec.hostNetwork | 定义是否使用主机网络模式,默认false,true表示使用宿主机网络,不使用docker网桥,意味着无法启动副本 |
kubectl explain xxx查看更多
样例
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
# namespace: default
labels:
k: v
spec:
containers:
- name: app
image: myapp
kubectl create -f xxx.yaml运行指定资源清单文件
kubectl describe pod xxx 查看pod相关信息
kubectl log xxx -c xxxx 查看xxxpod下xxxx容器的日志
kubectl get pod -o wide查看详细信息
POD的生命周期
- 创建pause
- 串行启动一些初始化容器,这些容器完成一些操作完后结束(init C)
- 主容器(开始start、就绪检测readiness、生存检测liveness、结束stop)
init c模板
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
# namespace: default
labels:
k: v
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
# 等待前置服务启动成功
initContainers:
- name: init-myservice
image: busybox
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']
- name: init-mydb
image: busybox
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
kubectl create -f myapp.yaml
kubectl get pod 查看为Init:0/2
kubectl describe pod myapp 查看到init containers为running
kubectl logs pod myapp-pod -c init-myservice查看initC容器日志
# 创建上面需要的service
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
容器探针
方法:
- ExecAction:在容器内执行指定命令。返回0代表ok
- TCPSocketAction:对指定容器端口做TCP检查,如果端口打开则ok
- HTTPGetAction:对指定容器端口执行GET,返回在 [200, 400) 认为ok
策略:
- livenessProbe:是否运行;如果存活探测失败,则kubectl会杀死该容器,并且容器将受到其重启策略的影响。默认为
Success - readinessProbe:是否准备好服务;如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为
Failure,不提供则默认为Success
容器探针模板
HTTPGet
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
spec:
containers:
- name: readiness-http-container
image: busybox
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1 # 启动后1s开始检测
periodSeconds: 3 # 多少秒后重试
exec
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox
imagePullPolicy: IfNotPresent
command: ['/bin/sh', '-c', 'touch /tmp/live; sleep 60; rm -rf /tmp/live; sleep 3600']
livenessPorbe:
exec:
command: ['test', '-e', '/tmp/live']
initialDelaySeconds: 1
periodSeconds: 3
TCPSocket
livenessPorbe:
tcpSocket:
prot: 80
timeoutSeconds: 1
initialDelaySeconds: 1
periodSeconds: 3
启动、退出-模板
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
namespace: default
spec:
containers:
- name: lifecycle-demo-container
image: nginx
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command: []
preStop:
exec:
command: []
Pod控制器
意义:无控制器管理的pod在退出后不会被拉起,而控制器管理下的pod在控制器的生命周期内会被始终维持其副本数量
控制器类型
Replication Controller & ReplicaSet & Deployment (无状态)
确保容器应用的副本数始终保持在用户定义的副本数,不多不少
RC已不再使用
RS同RC,但支持集合式的selector (通过标签选中一些Pod)
Deployment用来自动管理RS
StatefulSet(有状态)
稳定的持久化存储、稳定的网络标志、有序部署、有序收缩
DaemonSet
确保全部(或者一些)Node上运行一个Pod的副本。删除DaemonSet将会删除它创建的所有Pod
Job & CronJob
Job负责批处理任务,即仅执行一次的任务,保证批处理任务的Pod成功结束
Cron就是cron
ReplicaSet 模板
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend # 如果一个pod拥有这个标签,那么归这个RS管
template: # pod模板
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
查看pod并显示标签 kubectl get pod --show-labels
删除所有RS kubectl delete rs --all
Deployment 模板
其中创建了一个 ReplicaSet,负责启动三个 nginx Pods
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template: # pod-template
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
为这个deployment创建一个service kubectl expose deployment/nginx-deployment 。等价于:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
labels:
app: nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: nginx-deployment
服务(Service)发现
根据标签自动匹配存活的Pod,并对外统一转发服务
Type
ClusterIp:默认类型,自动分配一个仅集群内部可访问的虚拟IPNodePort:在ClusterIp的基础上为Service在每台宿主机上绑定一个端口,这样就可以通过NodeIp:NodePort来访问服务LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部负载均衡器,并将请求转发到NodeIP:NodePortExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用,没有任何类型代理被创建
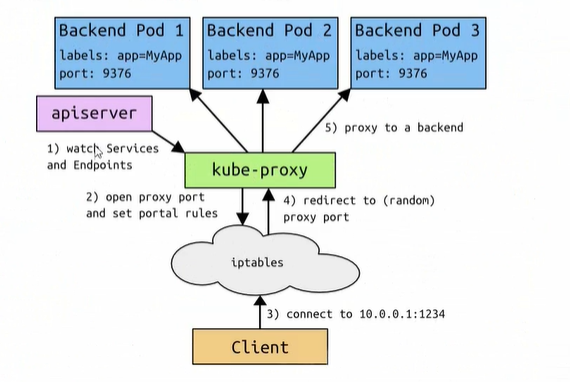
ClusterIP
需要以下几个组件的协同工作:
- apiserver:用户向apiserver发送创建service的命令,apiserver收到请求后将数据存储到etcd中
- kube-proxy:k8s每个节点都有一个叫kube-proxy的进程,这个进程负责感知service、pod的变化,并将变化的信息写入到本地iptables规则中
- iptabels:使用NAT等技术将virtualIP的流量转发至pod
样例见上节
NodePort
在node上开启一个端口,将进入该端口的流量转发至kube-proxy进一步转发至Pod
样例
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- port: 80 #虚拟IP里的port
targetPort: 80 #转发到pod的端口
# nodePort: 不指定时随机
selector:
run: nginx-deployment
存储
调度器
集群安全机制
HELM
类似yum,部署一些部件到集群中
运维
构建高可用集群
节点实例最好是单数,避免投票不出结果